Data Distribution: Replication, Sharding, and CAP & PACELC
Learning Objectives
- You know of replication and sharding and how they can be used to distribute data over multiple servers.
- You understand the CAP Theorem and the PACELC Theorem, and their implications for distributed systems.
- You know the tradeoffs between consistency, availability, and partition-tolerance in distributed systems.
Replication and sharding
There are two primary ways to distribute database data over multiple servers:
- Data replication, where the entire data set is copied to two or more servers, each maintaining a full copy.
- Data sharding, where the data set is split into shards (subsets), with each server responsible for storing one or more shards.
You may also come across the term data partitioning used more generally. In many contexts, data partitioning means splitting tables into smaller parts (partitions) within a single database server to improve performance. By contrast, data sharding typically refers to distributing data across multiple database servers. In other words, all sharding is a form of partitioning, but not all partitioning is sharding.
Data replication
In data replication, the database is fully copied to multiple servers (replicas). This improves fault tolerance and availability, because the system can keep running if one replica fails. However, replication requires coordination to keep all replicas consistent.
There are two key approaches to coordinating updates:
- Primary-Secondary Replication (Single-Writer, Multi-Reader)
- One server (the primary) handles all write operations.
- One or more secondary servers handle read operations.
- When a write occurs on the primary, it propagates (replicates) changes to the secondaries.
- Primary-Primary Replication (Multi-Writer, Multi-Reader)
- All servers can accept writes.
- The servers coordinate to ensure they apply updates in the correct order (often more complex due to synchronization).
Figure 1 shows primary-secondary replication, where one replica (the primary) handles writes, and the other replica(s) handle reads.
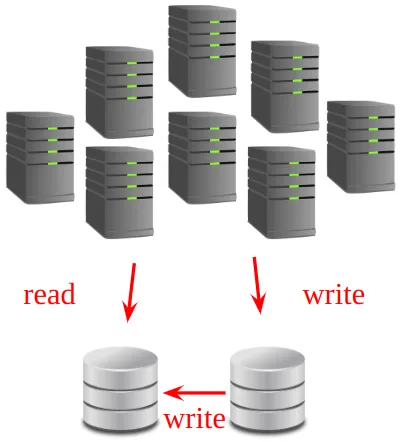
In a primary-secondary system, losing a secondary typically does not affect availability because the primary is still alive and new secondary systems can be spawned if needed. Losing the primary, however, can be more serious. In that scenario, one of the secondaries must be promoted to primary; Depending on the replication mode (synchronous vs. asynchronous), this may lead to potential data loss during the failover process.
In contrast, primary-primary replication allows all replicas to handle both reads and writes, which can improve write scalability but requires robust coordination protocols (e.g., consensus algorithms) to guarantee correctness and ordering of updates.
When considering the primary-secondary replication, the primary database is responsible for making sure that the content is written to the secondary database(s) in the correct order. However, in the case of primary-primary replication, where data can be written to any server, the servers need to coordinate to ensure that the data is written in the correct order. This is more complex, as it requires more data to be updated between servers.
Data sharding
In data sharding, the database is divided into shards, each stored on a different server. This is often called horizontal partitioning. For example, you might shard users by user ID ranges or partition timestamps into date-based shards.
Sharding can improve performance for queries that only need to access one shard (one server) rather than scanning a massive table with all the data. However, queries that span multiple shards need to coordinate data from multiple servers, increasing latency and complexity.
When using data sharding, if the server hosting a shard fails, that shard is unavailable until the server is restored. This can be mitigated by replicating each shard across multiple servers.
Another challenge is load balancing: Some shards may become “hotspots”, receiving a disproportionately large workload. A common strategy to mitigate uneven distribution is consistent hashing when forming shards. Consistent hashing helps spread data more evenly and reduces the amount of data movement when adding or removing shards. However, in some cases, especially with non-uniform data access patterns, consistent hashing can still result in uneven data distribution. This may require additional strategies, such as virtual nodes or dynamic re-sharding, to achieve optimal balance.
Figure 2 illustrates an example of data sharding by distributing data based on a range of values.
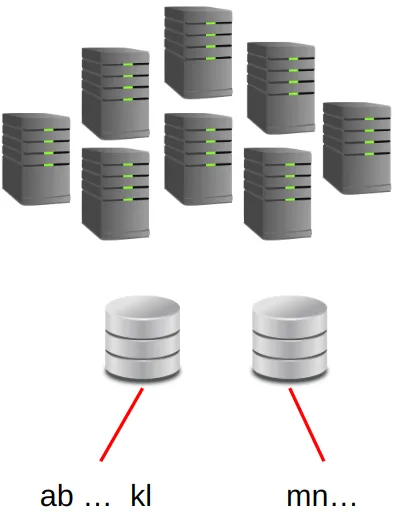
Combining replication and sharding
Many large-scale systems use both sharding and replication. First, they split the data into shards and then replicate each shard across multiple servers. This approach provides better fault tolerance and availability because each shard is redundantly stored. However, it also raises complexity for consistency and maintenance: updates must propagate correctly to all replicas of the relevant shard.
Figure 3 highlights an example where each shard is replicated.
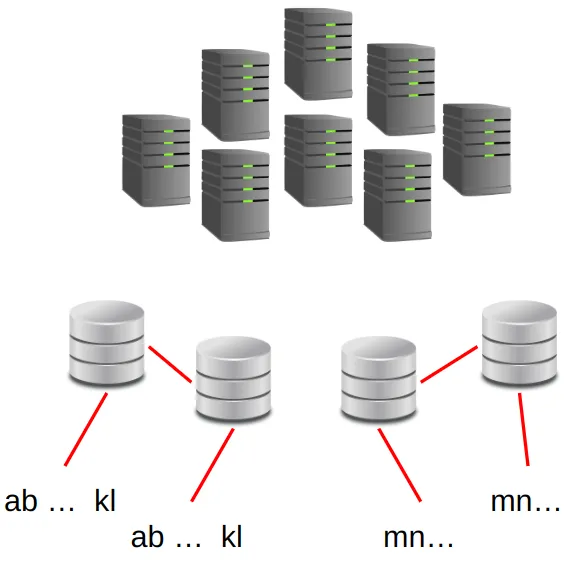
As an example, Google’s AlloyDB and Cloud Spanner use both data replication and data sharding.
Consensus protocols such as Paxos are used to ensure replicas apply updates in a consistent order. Discussing these protocols in detail is beyond the scope of this course, but they are crucial for maintaining correctness in multi-replica writes.
CAP and PACELC Theorems
When a system becomes distributed across multiple networked servers, network partitions (temporary breaks or isolations in the network) will eventually happen. In such scenarios, designers of distributed systems must make tradeoffs between the availability of the application and the consistency of its data.
According to the CAP Theorem, a fully distributed system can reliably offer at most two out of the following three under all failure scenarios.
- Strong Consistency — all servers have the same data at the same time.
- High Availability — every request receives a response about whether it succeeded or failed.
- Partition Tolerance — the system continues to operate despite network partitions.
As network partitions are inevitable, in practice, distributed systems must choose between availability and consistency when a partition occurs. Thus, over the years, the key question in distributed database systems has evolved into How do we achieve both high availability and strong consistency, as much as possible?
See also CAP Twelve Years Later: How the “Rules” Have Changed.
To refine these concepts, the PACELC theorem says that if a partition (P) happens, a system must choose between availability (A) and consistency (C). Else (E), the system must decide whether to optimize for latency (L) or consistency (C). The theorem highlights that even without a partition, you often trade off latency vs. strong consistency.
Many modern cloud-scale databases like Google Spanner employ advanced replication, consensus protocols, and sophisticated shard balancing to get “the best of both worlds”. However, the fundamental CAP constraints still apply in partitioned or failure scenarios.