HTTP and Caching
Learning Objectives
- You refresh your understanding of the client-server model and HTTP.
- You know the key features and improvements across HTTP/1.0, HTTP/1.1, HTTP/2, and HTTP/3.
- You understand the role and implementation of caching headers in HTTP.
Client-Server Model and HTTP
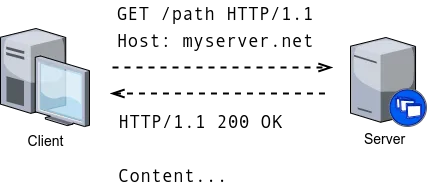
Client-server model is the base model of web applications, where clients (typically browsers) request resources from servers. The communication between the client and the server is based on HTTP (HyperText Transfer Protocol). The high-level view is summarized in Figure 1.
HTTP is a stateless protocol. Each HTTP request is independent, meaning the server does not retain session information between requests. Additional mechanisms like cookies or tokens are used to maintain state when necessary.
Evolution of HTTP/1 and HTTP/2
The protocol has evolved over time, with the following key versions:
-
HTTP/1.0: Each request-response pair required a new TCP connection, leading to additional latency due to every request requiring a TCP handshake. The protocol had a
keep-aliveheader, allowing persistent connections, but this was not the default behavior and servers typically closed connections after each request. -
HTTP/1.1: Made persistent connections with
keep-aliveheader the default behavior, reducing overhead by sending multiple requests over a single TCP connection. HTTP/1.1 also made theHostheader mandatory, allowing multiple websites to be hosted on a single server.
When retrieving information from a server, clients could initiate multiple connections per server to parallelize requests. The RFC2616 specification for HTTP/1.1 explicitly recommended limiting the number of simultaneous connections to a server to avoid congestion (the RFC has been since superceded).
While the same TCP connection can be used to send multiple, the requests are sent sequentially. This means that a single slow request can slow or block subsequent requests, which is known as head-of-line blocking.
- HTTP/2: Introduced multiplexing, allowing multiple requests to be sent over a single connection simultaneously, eliminating head-of-line blocking within HTTP. The protocol also compresses HTTP headers, reducing overhead, and supports server push, where the server can send resources to the client over an existing connection without a request. In addition, HTTP/2 transforms HTTP into a binary protocol, which simplifies parsing and reduces errors, and provided the possibility to prioritize streams to ensure that critical resources are loaded first.
Despite HTTP/2 eliminating head-of-line blocking within HTTP, the protocol relies on TCP which can experience head-of-line blocking: if a TCP packet is lost, all subsequent packets must wait until the lost packet is retransmitted and received. There have been, however, suggestions to improve this (see e.g. RFC6582).
Establishing a TCP connection takes three messages, known as a 3-way handshake. Once the TCP connection is established, the connection is secured using additional messages, where the client and the server agree on a secure key for communication. This process is known as the TLS handshake. With the commonly adopted TLS 1.3, the handshake has two or more messages, depending on the configuration.
The TCP 3-way handshake and the TLS handshake are done for every new connection in HTTP/1.1 and HTTP/2.
HTTP/3 and QUIC
HTTP/3 addresses the limitations of HTTP/2 by using the QUIC (Quick UDP Internet Connections) protocol, which is built on top of UDP (User Datagram Protocol). Similar to HTTP/2, HTTP/3 has multiplexing, header compression, and server push. In addition, QUIC introduces connection migration, allowing clients to switch between networks without losing the connection.
QUIC integrates TLS 1.3 for secure connections, where initiating a new connection involves only a single round trip, reducing latency compared to TCP and TLS. Subsequent connections can use previously established connection information, reducing overhead related to establishing the connection.
Although the protocol has evolved over time, the semantics of HTTP have remained the same. The protocol is based on a request-response model, where the client sends a request to the server, and the server responds with the requested resource.
The request consists of a method (e.g. GET), a path (e.g. /index.html), and headers (e.g. Host). The response consists of a status code (e.g. 200 OK), headers (e.g. Content-Type), and the response body (e.g. HTML, JSON).
Performance, Availability, and Summary
The performance of HTTP versions can be measured in terms of latency, throughput, and time-to-first-byte. HTTP/2 and HTTP/3 have shown improvements over HTTP/1.1, with HTTP/3 being the most recent and most performant version. The performance differences become especially evident with web applications that consist of multiple resources, as the multiplexing and binary compression features of HTTP/2 and HTTP/3 can significantly reduce latency.
As an example, the Amazon.com website makes over 300 requests to load the main page. If each of these requests would require a new TCP connection, the perceived performance of the site would be significantly poorer.
In January 2025, approximately 35% of all websites support HTTP/2, and approximately 34% support HTTP/3. Similarly, approximately 98% of all internet users have a browser that supports HTTP/2, while approximately 95% have support for HTTP/3.
The HTTP versions are summarized in the table below.
| Feature | HTTP/1.0 | HTTP/1.1 | HTTP/2 | HTTP/3 |
|---|---|---|---|---|
| Transport Protocol | TCP | TCP | TCP | QUIC (UDP) |
| Connection Management | New TCP connection per request | Persistent connections by default | Multiplexed multiple requests over a single connection | Multiplexed multiple requests over a single connection, Connection migration |
| Persistent Connections | Optional via Keep-Alive header, but not really supported | Default behavior | Default behavior | Default behavior |
| Header Compression | No | No | Yes | Yes |
| Multiplexing | No | No | Yes | Yes |
| Server Push | No | No | Yes | Yes |
| Binary Protocol | No | No | Yes | Yes |
| Head-of-Line Blocking | Not applicable | Yes | No (within HTTP), Yes (in TCP) | No |
Caching and HTTP Headers
When users visit web applications, they often revisit the same applications, and navigate between the pages of the application. Revisiting a page leads to a request for the same resources, such as images, stylesheets, and scripts. To improve the performance of web applications, HTTP headers can be used to instruct clients to cache resources locally, reducing the need to retrieve the same resources multiple times.
The three main headers for caching are Cache-Control, Last-Modified, and ETag. HTTP caching is outlined in RFC9111.
Cache-Control
The Cache-Control header is used to enable caching for a resource and, optionally, to set an age for the resource. As an example, when asking for a resource at /images/retro-sax-guy.gif, the HTTP request could be as follows.
GET /images/retro-sax-guy.gif HTTP/1.1(headers)While the response, with Cache-Control header, could be as follows.
HTTP/1.1 200 OKCache-Control: private, max-age: 86400
... data ...The max-age option in the header is given in seconds. Now, based on the response, the resource /images/retro-sax-guy.gif could be cached by the client, and the client would not need to retrieve the resource during the next 24 hours (24*60*60 = 86400).
That is, when the users accesses the page, the browser loads the page and the resources, adding the image to the cache. If the user loads the page again within the 24 hours, the browser would not even attempt to retrieve the image.
The
Cache-Controlheader can also be used to disable caching, by setting themax-ageto0and by adding theno-storeoption to the header. Theno-storeoption indicates that the resource should not be stored in the cache, and themax-ageof0indicates that the resource should not be cached.
Last-Modified (and If-Modified-Since)
The Last-Modified header provides additional information about the resource being retrieved. When the Last-Modified header is used, the server responds with information on when the requested resource was last changed.
Again, when retrieving the resource at /images/retro-sax-guy.gif, the request could be as follows.
GET /images/retro-sax-guy.gif HTTP/1.1(headers)When the Last-Modified header is in use, the response would be as follows — in the example below, we’ve also included the Cache-Control header, as they are typically used jointly.
HTTP/1.1 200 OKCache-Control: private, max-age: 86400Last-Modified: Fri, 24 Feb 2017 11:45:00 GMT
... data ...Now, based on the response, the browser would know not to even attempt to retrieve the resource in the next 24 hours. After that, when attempting to retrieve the resource, the browser sends information about the known last modified date of the resource, which was previously received as a part of the response from the server. The header that contains the last modified date in the request is If-Modified-Since.
That is, after the 24 hour no-retrieve break indicated by Cache-Control, the browser would again start retrieving the resource. This time, however, the request would have information about the resource, which the server then can use to decide whether the data has been modified. A request would look as follows.
GET /images/retro-sax-guy.gif HTTP/1.1If-Modified-Since: Fri, 24 Feb 2017 11:45:00 GMT(further headers)Now, when the server receives such a request, it can compare the date in the If-Modified-Since header with the actual modification date of the resource. If the resource has been modified since, the response would contain the data and a new Last-Modified header, as follows.
HTTP/1.1 200 OKCache-Control: private, max-age: 86400Last-Modified: Fri, 04 Oct 2019 09:45:00 GMT
... data ...On the other hand, if the resource would not have been modified, there is no need to send the data again. In this case, the server could return a response with the status code 304, indicating that the resource has not been modified.
HTTP/1.1 304 Not Modified(headers)ETag (and If-None-Matches)
The ETag header provides an unique identifier matching the resource that is being retrieved. It is generated on the server to correspond to the resource, and sent to the client. When using the ETag header, the initial HTTP request is again similar to the previous HTTP requests.
GET /images/retro-sax-guy.gif HTTP/1.1(headers)With a server supporting the ETag header, the response could be as follows. The unique identifier-from-server would be a string representation of the content of the requested resource (e.g. MD5 or CRC32C checksum of the contents of the resource).
HTTP/1.1 200 OKCache-Control: private, max-age: 86400ETag: "unique-identifier-from-server"
... data ...Now, when the client retrieves the resource for the next time (after the initial 24 hour delay determined in Cache-Control), the request for the resource would have a header If-None-Match that would contain the value previously received from the server.
GET /images/retro-sax-guy.gif HTTP/1.1If-None-Match: "unique-identifier-from-server"Similarly to the Last-Modified header, when the server receives a request with If-None-Match, it can compare the value in the If-None-Match header with the actual ETag of the resource. If the value of If-None-Match and the ETag do not match, the response would contain the data and a new ETag header, as follows.
HTTP/1.1 200 OKCache-Control: private, max-age: 86400ETag: "another-unique-identifier-from-server"
... data ...If the resource would not have been modified, there would be no need to send the data again. The server would again indicate this with the status code 304.
HTTP/1.1 304 Not Modified(headers)When compared with the Last-Modified header, the benefits of the ETag header include granularity. If a resource changes twice within a second, the use of the Last-Modified header could lead to stale cache, as the granularity of the format is in seconds. For ETag, the value would be changed whenever the resource would change.
Both Last-Modified and ETag can also be used to track users (although due to the granularity of Last-Modified, ETag better suits this purpose). When a browser requests a resource, the server can, e.g., add a unique ETag per user-resource -pair, and use subsequent requests to follow the movement of individual users. This could effectively be used to bypass cookies (or sessions).
The use of a variety of headers for tracking users has been identified in research studies (see e.g. Flash Cookies and Privacy II: Now with HTML5 and ETag Respawning). Such use has also led to lawsuits (see e.g. Privacy suit filed over use of ETags).
Support from servers
When working with web applications, the protocol and the caching headers are typically handled by the server, and developers rarely have to implement the caching logic. To illustrate how caching works with Hono and Deno, create an application with the following file structure.
.├── app.js├── deno.json└── index.htmlPlace the following content in the index.html file.
<html> <head> <title>Hello, etag!</title> </head> <body> <p>Hello, etag!</p> </body></html>The following to deno.json (we’re just using Hono).
{ "imports": { "@hono/hono": "jsr:@hono/hono@4.6.5" }}And the following to app.js.
import { Hono } from "@hono/hono";import { serveStatic } from "@hono/hono/deno";const app = new Hono();
app.use(serveStatic({ root: "./" }));
Deno.serve(app.fetch);The above creates an application that responds to requests with static files from the root folder of the application. To start the server, run the following command.
deno run --allow-net --allow-read app.jsHTTP/2 support
Curl supports making HTTP/2 requests with the —http2-prior-knowledge flag, which makes a request assuming that the server supports HTTP/2. To see if the server supports HTTP/2, let’s make a request to the server.
curl -v --http2-prior-knowledge localhost:8000/index.html// ...* Using HTTP2, server supports multiplexing* Connection state changed (HTTP/2 confirmed)* Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0* Using Stream ID: 1 (easy handle 0x5b1923735e90)> GET /index.html HTTP/2// ...* Connection state changed (MAX_CONCURRENT_STREAMS == 200)!< HTTP/2 200< content-type: text/html; charset=utf-8< vary: Accept-Encoding< date: Thu, 30 Jan 2025 08:42:13 GMT// ...The response headers include the HTTP/2 string, indicating that the server supports HTTP/2.
We could have also just looked into Deno documentation to see this — Deno.serve supports both HTTP/1.1 and HTTP/2.
Etag header
Let’s next add functionality for the ETag header. Hono has an ETag middleware that can be used to add the ETag header to the response. To add the middleware, modify the app.js file to match the following.
import { Hono } from "@hono/hono";import { serveStatic } from "@hono/hono/deno";import { etag } from "@hono/hono/etag";
const app = new Hono();
app.use(etag());app.use(serveStatic({ root: "./" }));
Deno.serve(app.fetch);Above, we create an application that applies the etag middleware to all requests, and that responds to requests with static files from the root folder of the application.
Now, when we restart the server and make a request to it, we see that the response headers include the etag header.
curl -v localhost:8000/index.html// ...< etag: "552c881e5d307f0868e3b23664a1481245abd577"<<html> <head> <title>Hello, etag!</title> </head> <body> <p>Hello, etag!</p> </body></html>The middleware takes care of checking for the resources and adding the ETag header to the response. The middleware also checks if the resource has been modified since the last request, and if not, responds with the status code 304. That is, if we make a request to the server with the If-None-Match header with a corresponding value, we see that the server responds with the status code 304, indicating that we can use the resource that we already have.
curl -H 'If-None-Match: "552c881e5d307f0868e3b23664a1481245abd577"' -v localhost:8000/index.html// ...> GET /index.html HTTP/1.1> If-None-Match: "552c881e5d307f0868e3b23664a1481245abd577"// ...< HTTP/1.1 304 Not Modified< etag: "552c881e5d307f0868e3b23664a1481245abd577"Cache-Control header
Similarly, the cache middleware can be used to add the Cache-Control header to the response. We previously used the middleware when caching resources on the server.
The following application would add both the etag header and the cache-control header to responses. The cache-control header sets the max-age option to 24 hours.
import { Hono } from "@hono/hono";import { serveStatic } from "@hono/hono/deno";import { etag } from "@hono/hono/etag";import { cache } from "@hono/hono/cache";
const app = new Hono();
app.use( cache({ cacheName: "my-app", cacheControl: "max-age=86400", wait: true, }),);app.use(etag());app.use(serveStatic({ root: "./" }));
Deno.serve(app.fetch);Now, after the server is restarted and we make a request to the server, we see that the response headers include both the ETag and the Cache-Control headers.
curl -v localhost:8000/index.html// ...< HTTP/1.1 200 OK< cache-control: max-age=86400< etag: "552c881e5d307f0868e3b23664a1481245abd577"// ...<html> <head> <title>Hello, etag!</title> </head> <body> <p>Hello, etag!</p> </body></html>Cache-control in action
Now, download an image and place it in the same folder with the index.html. If you’re not sure what to pick, you can e.g. download a duck picture from https://tenor.com/view/dancing-random-duck-gif-25973520 — here, we assume that the picture is called duck.gif and is placed in the same folder as the index.html.
Now, modify the index.html to include a reference to the image.
<html> <head> <title>Hello, duck!</title> </head> <body> <p>Hello, duck!</p> <img src="duck.gif" /> </body></html>Restart the server and make a request to the server. You’ll likely see the old index.html instead of the above, as we have asked Hono to cache the resources. To see the new index.html, change the cache name in the app.js to my-duck-app, and restart the server.
import { Hono } from "@hono/hono";import { serveStatic } from "@hono/hono/deno";import { etag } from "@hono/hono/etag";import { cache } from "@hono/hono/cache";
const app = new Hono();
app.use( cache({ cacheName: "my-duck-app", cacheControl: "max-age=86400", wait: true, }),);app.use(etag());app.use(serveStatic({ root: "./" }));
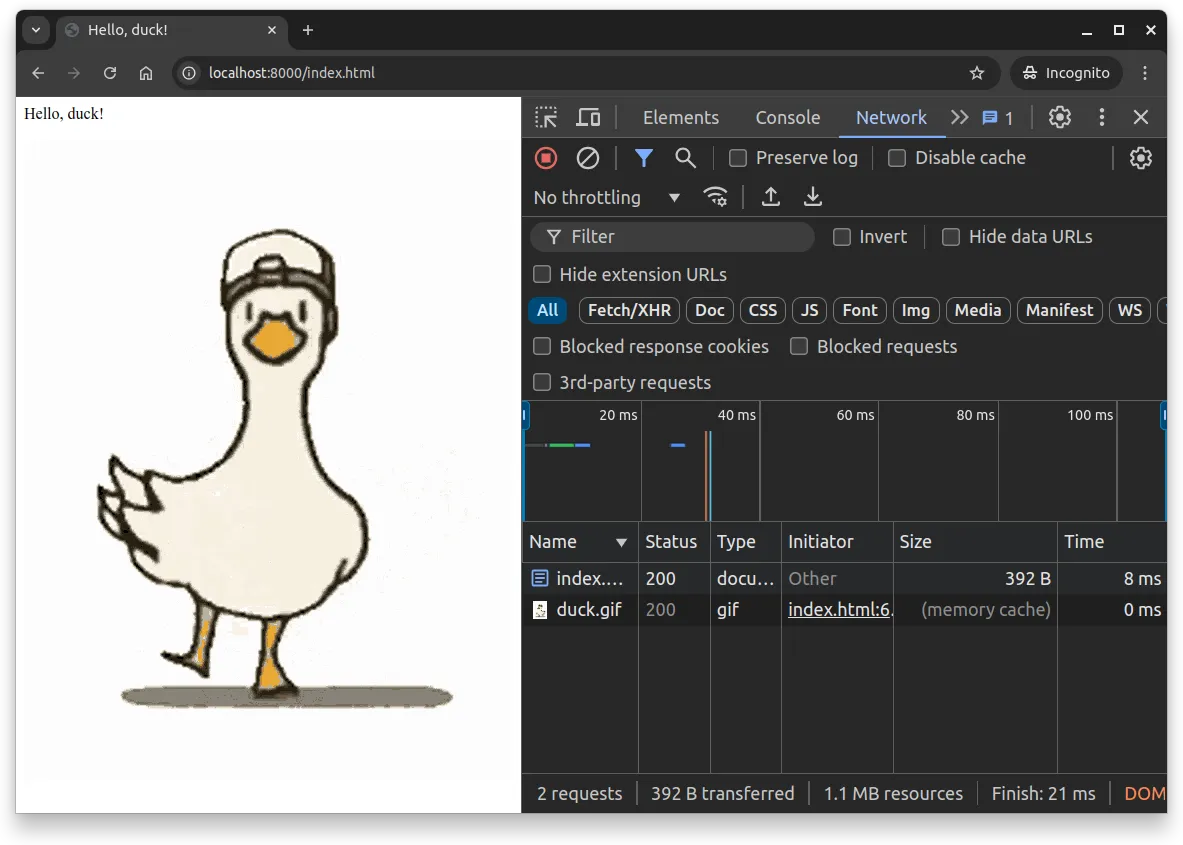
Deno.serve(app.fetch);Now, when you make a request to the server, you’ll see that the server responds with the index.html. In addition, when you open up the index.html in a browser, you’ll see the Hello, duck! text and the image. Importantly, if you open the developer tools, you’ll also notice that the duck.gif is cached. Any page reloads will lead to the image being retrieved from browser cache, which is indicated by the “Size” of the resource being (memory cache) and the time to retrieve the resource being zero milliseconds.
Figure 2 shows a screenshot of the developer tools with the network tab open, showing that the duck image is retrieved from the cache.